The tests included in this report show memory utilization and
speed for adds, deletions, and queries of Sesame and Kowari-based
triplestores.
Two large datasets were used for these tests.
Wordnet tests were conducted on a Windows XP machine with an AMD Athlon XP
2800 processor. IMDB tests were conducted on a Linux machine running
with 4 Intel(R) Xeon(TM) CPU 3.20GHz processors. All tests were
run using Sun's Java 1.4.2 JRE with default JVM settings.
The tests were performed using Tripletest,
a Java utility that uses Trippi v0.9.4
to provide a uniform add/query/delete interface to the triplestores being tested.
Triplestore Test Configurations:
- Kowari v1.0.5 - Running locally, using a triple buffer of size 30,000 for adds/deletes.
- Sesame v1.2RC2 - Running locally, using a triple buffer of size 500 for adds/deletes.
Both the native and the RDMBS sails were tested. For the RDBMS sail, a local
instance of MySQL 4.0.21-nt (with no special configuration) was used.
Inference capabilities were not tested.
Some graphs are plotted with logarithmic co-ordinates for readbility.
This is indicated by the scale on the graph as well as accompanying text
where applicable.
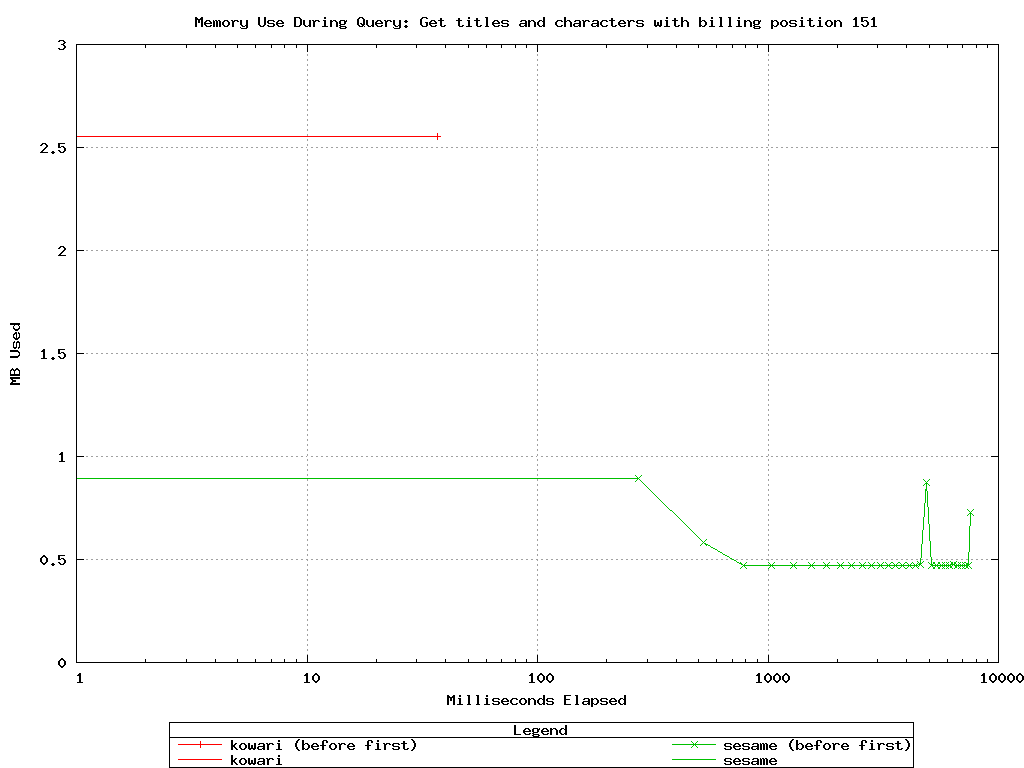
Query result graphs convey a lot of information, so they need a little
explanation: Memory utilization is measured at even increments of time
throughout the process of getting a query result set.
Before the first result is returned memory use is plotted with decorated
lines. After the first result is returned,
the lines are no longer decorated. From the X coordinates of the
lines, you can determine how long a query took 1) to return the
first result, and 2) to complete.
You can click any inline graph to see a 1024x768 version.
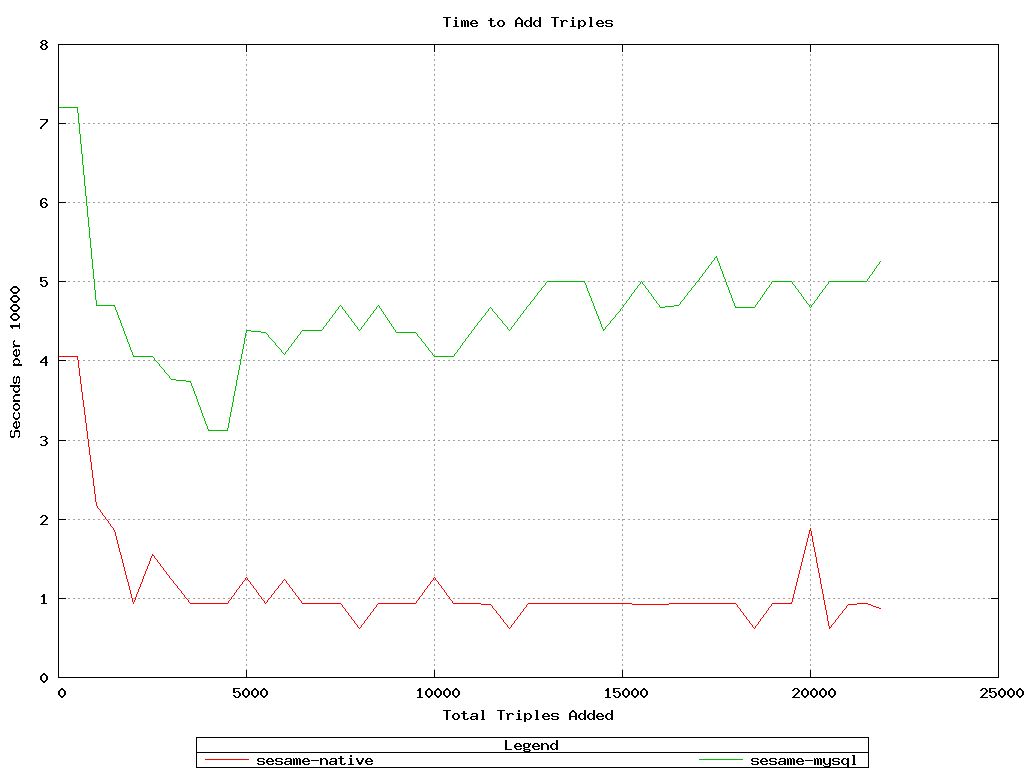
The first test was intended to quickly determine how the Sesame native sail's
add/delete speed compared to that of the Sesame RDBMS (MySQL) sail.
Sesame-native generally outperformed Sesame-MySQL in this test.
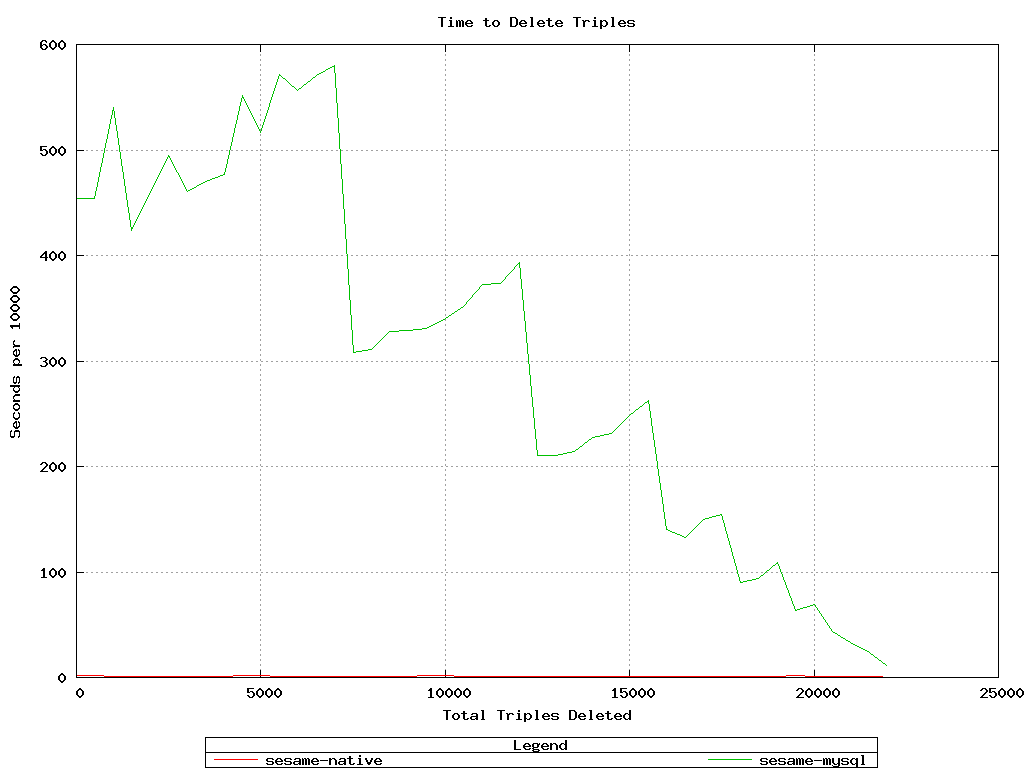
To find out why Sesame-MySQL was performing so poorly on deletes,
I logged the database queries being done by the RDBMS sail and found
that it was constantly making "OPTIMIZE TABLE" requests to MySQL.
Since this can be an expensive operation, I temporarily disabled these
OPTIMIZE requests but performance became worse as a result.
A quick look at the source code for this sail indicates that it uses
several temporary tables during the add and delete process. The necessity
of using temporary tables here is unclear. TODO: Ask the
Sesame developers about this.
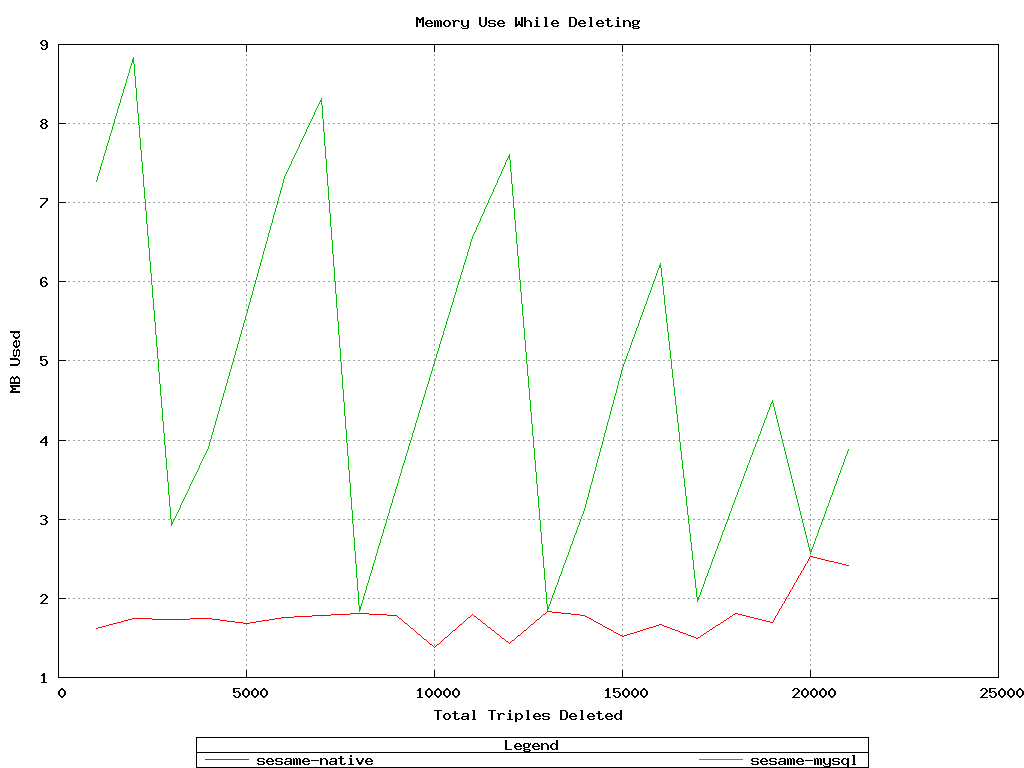
For adds, the native sail was about 5x faster.
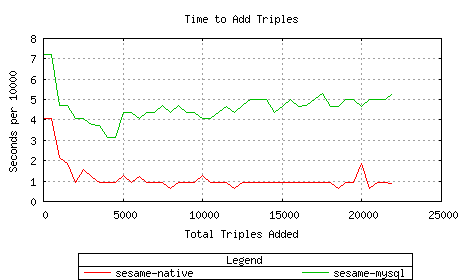
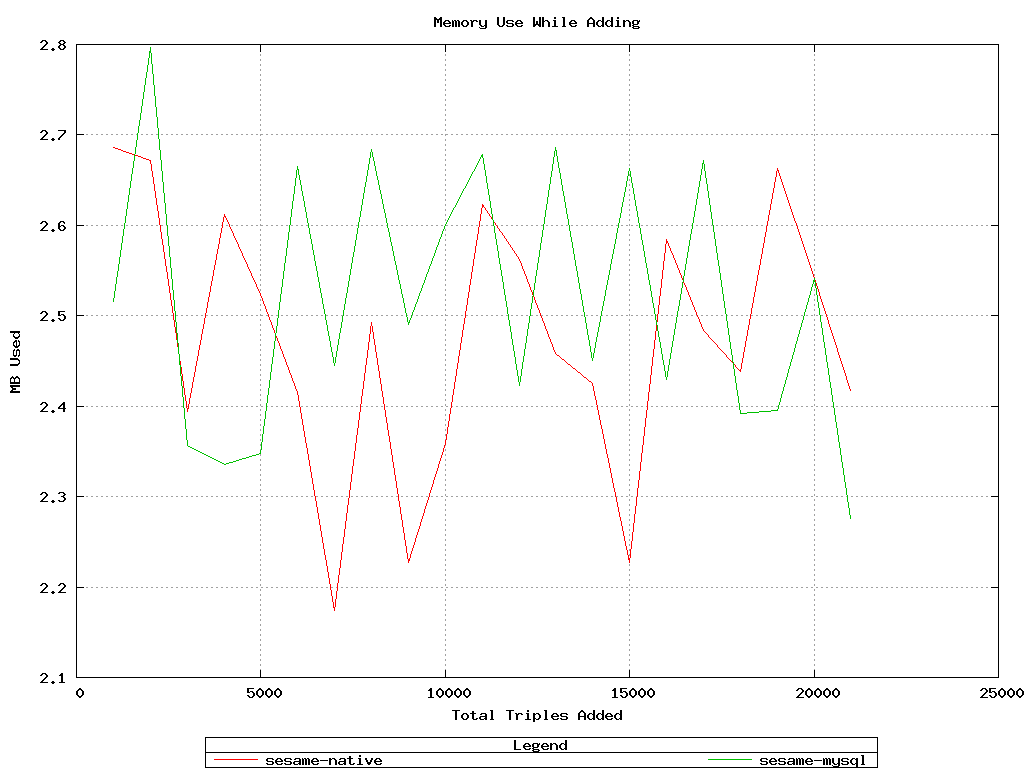
Memory usage while adding was roughly equivalent.
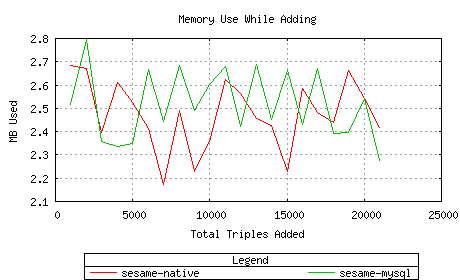
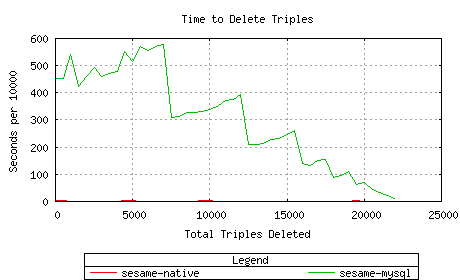
Sesame-MySQL took an inordinate amount of time with 20k triples,
finally decreasing to a rate of 11 seconds/10,000 while deleting the last
chunk of 500. Sesame-native stayed pretty constant at 1-to-2 seconds/10,000.
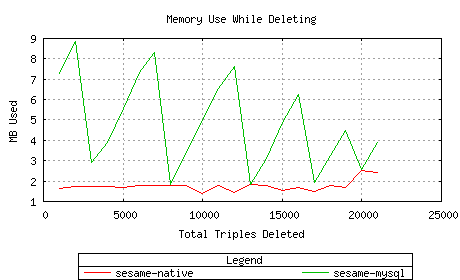
Memory usage while deleting was similar to the above: Sesame-MySQL required more
to start, then tapered off, while Sesame-native remained low.
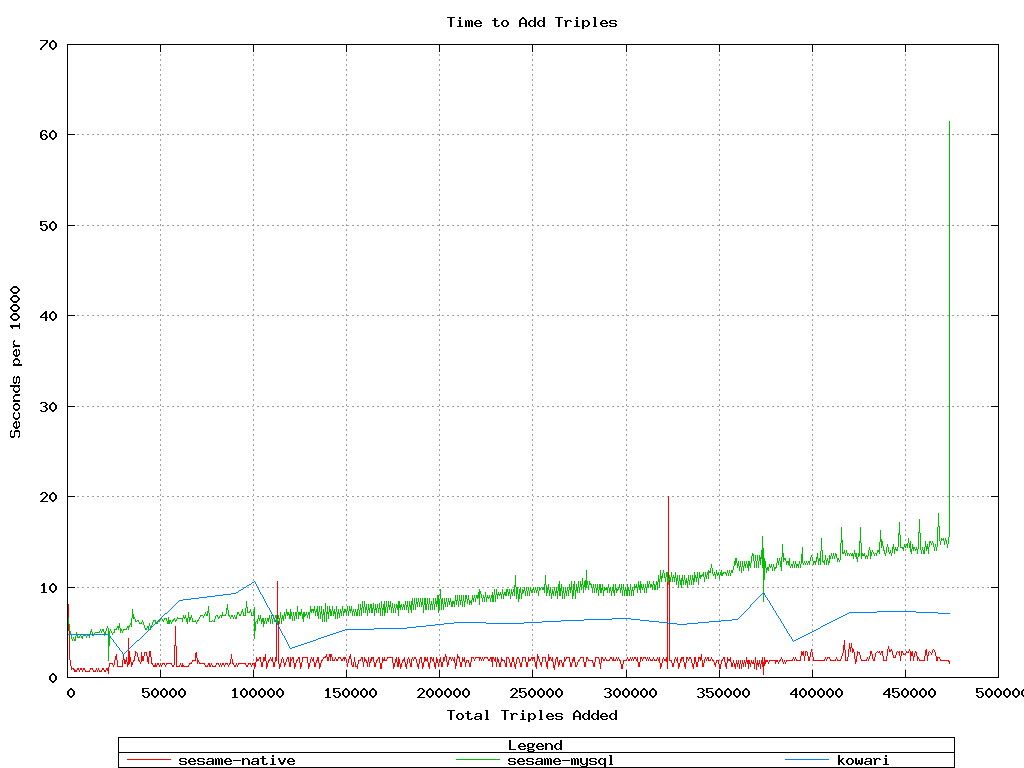
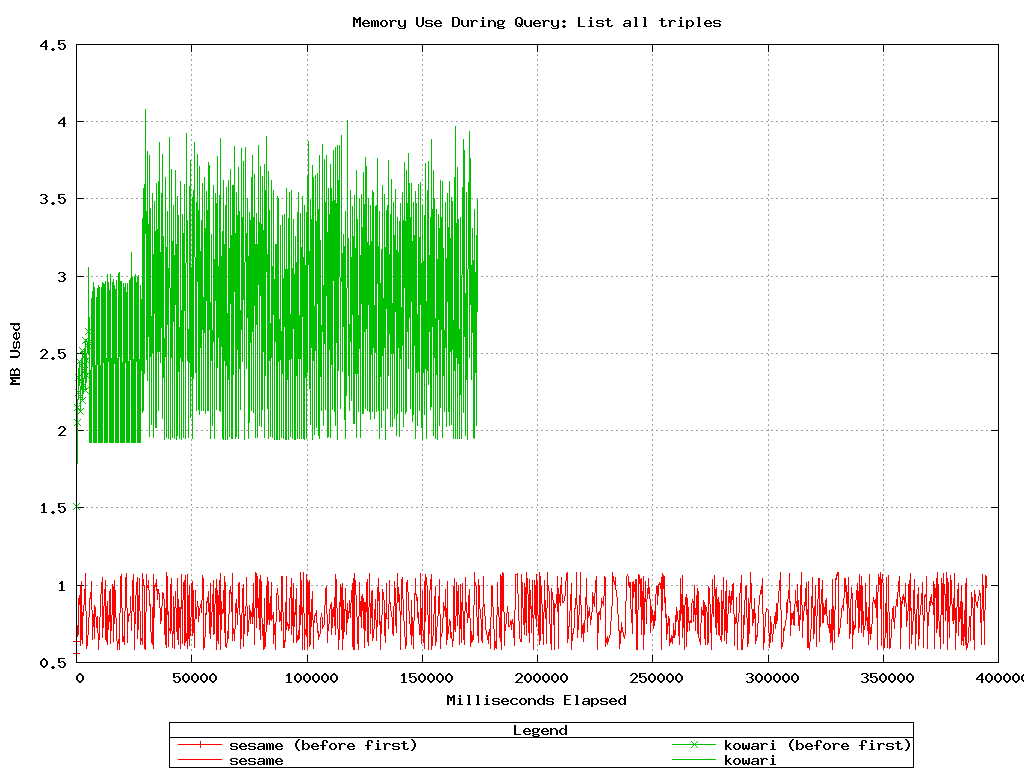
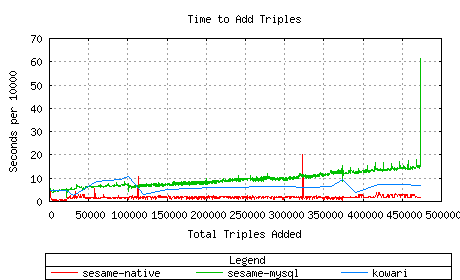
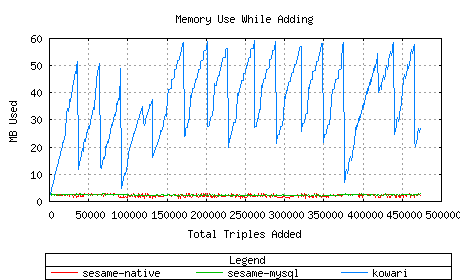
This test compares Sesame-native and Sesame-MySQL with Kowari for add
and query performance. Note that for adds and deletes, Kowari
has fewer datapoints than Sesame. This is due to the size of the
triple buffers. Kowari performs better with a large buffer,
whereas Sesame performs better with a smaller one.
Kowari is a bit slower to add triples than Sesame-native, but
faster than Sesame-MySQL.
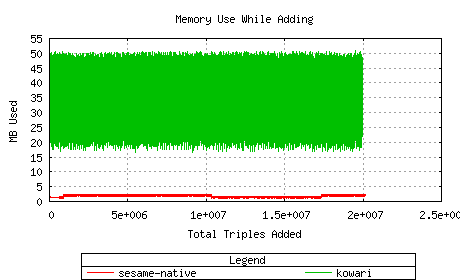
Kowari requires more memory, which makes sense, since its update buffer
is larger. Memory utilization is not alarming in any case.
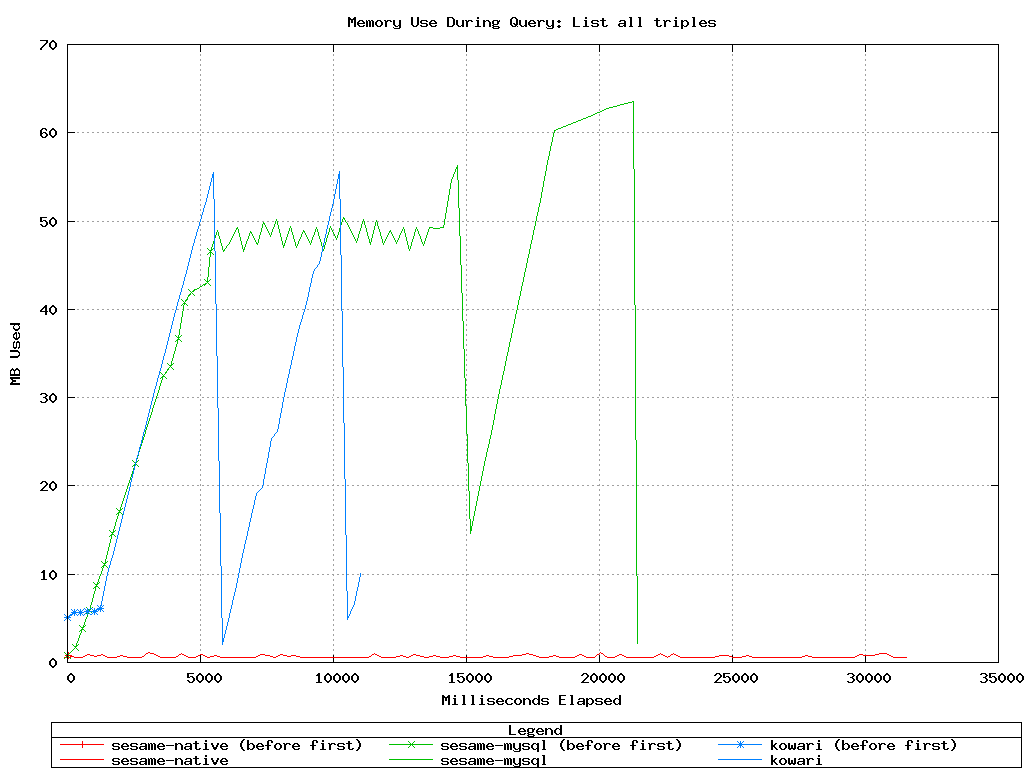
Query 1
Sesame (SPO) Query:
* * *
Kowari (SPO) Query:
* * *
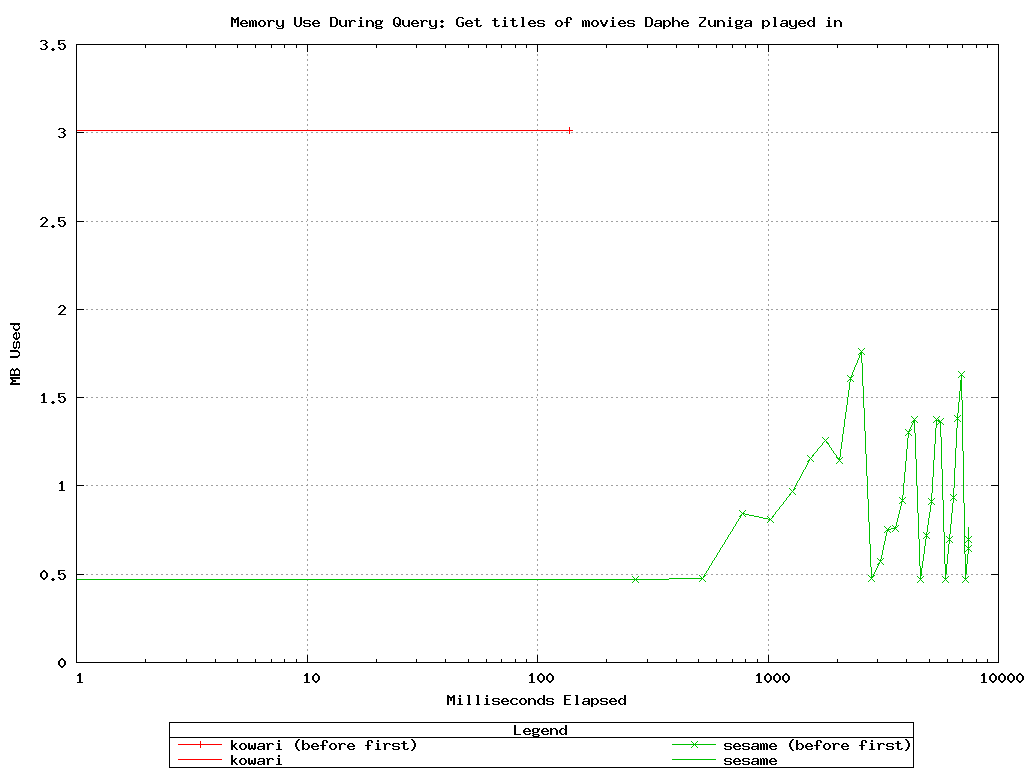
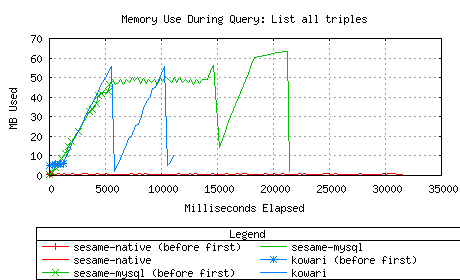
Kowari and Sesame-native both completed successfully, but
Sesame-MySQL failed with an out of memory error after 22 seconds.
This is similar to the result we saw with Jena on a previous test,
and similarly seems to be caused by not using streaming ResultSets from MySQL. See Sesame
Bug #59.
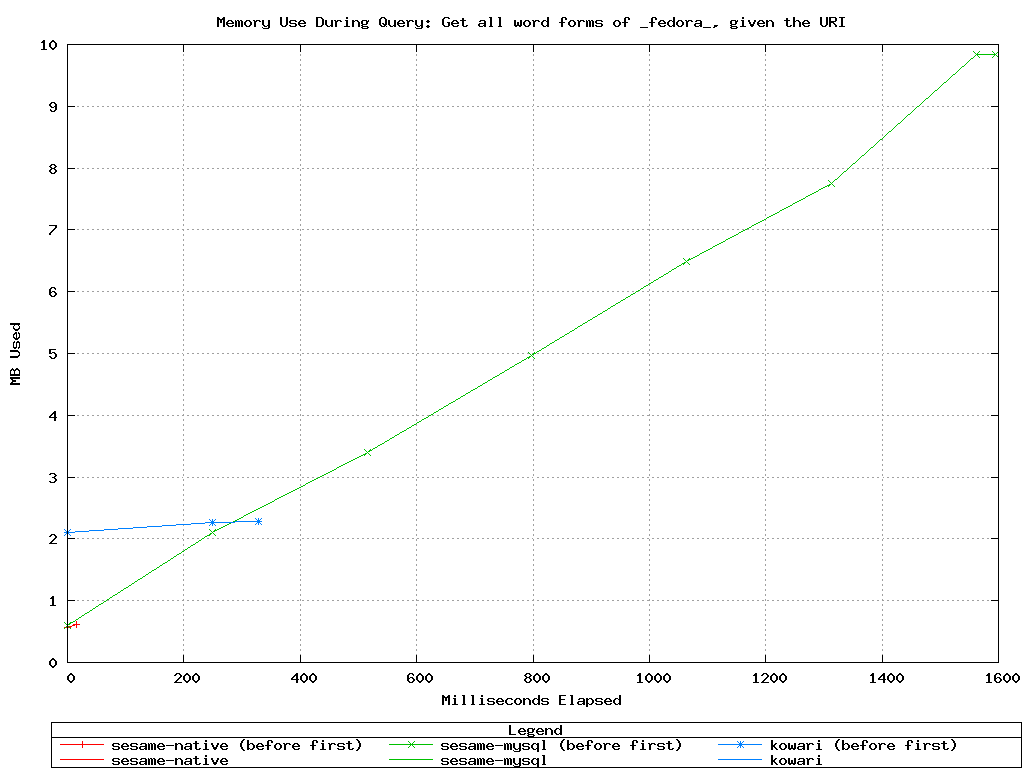
Query 2
Sesame (SeRQL) Query:
select word
from {wordnet:102669463} schema:wordForm {word}
Kowari (iTQL) Query:
select $word
from <#test>
where <wordnet:102669463> <schema:wordForm> $word
Query 3
Sesame (SeRQL) Query:
select word, definition
from {myConcept} schema:wordForm {"happy"};
schema:similarTo {thatConcept},
{thatConcept} schema:wordForm {word};
schema:glossaryEntry {definition}
Kowari (iTQL) Query:
select $word $definition
from <#test>
where $myConcept <schema:wordForm> 'happy'
and $myConcept <schema:similarTo> $thatConcept
and $thatConcept <schema:glossaryEntry> $definition
and $thatConcept <schema:wordForm> $word
Query 4
Sesame (SeRQL) Query:
select distinct word, superTypeA, superTypeB, superTypeC, superTypeD
from {concept} rdf:type {schema:Verb};
schema:hyponymOf {h1};
schema:wordForm {word},
{h1} schema:hyponymOf {h2};
schema:wordForm {superTypeA},
{h2} schema:hyponymOf {h3};
schema:wordForm {superTypeB},
{h3} schema:hyponymOf {h4};
schema:wordForm {superTypeC},
{h4} schema:wordForm {superTypeD}
Kowari (iTQL) Query:
select $word $superTypeA $superTypeB $superTypeC $superTypeD
from <#test>
where $concept <rdf:type> <schema:Verb>
and $concept <schema:hyponymOf> $h1
and $concept <schema:wordForm> $word
and $h1 <schema:hyponymOf> $h2
and $h1 <schema:wordForm> $superTypeA
and $h2 <schema:hyponymOf> $h3
and $h2 <schema:wordForm> $superTypeB
and $h3 <schema:hyponymOf> $h4
and $h3 <schema:wordForm> $superTypeC
and $h4 <schema:wordForm> $superTypeD
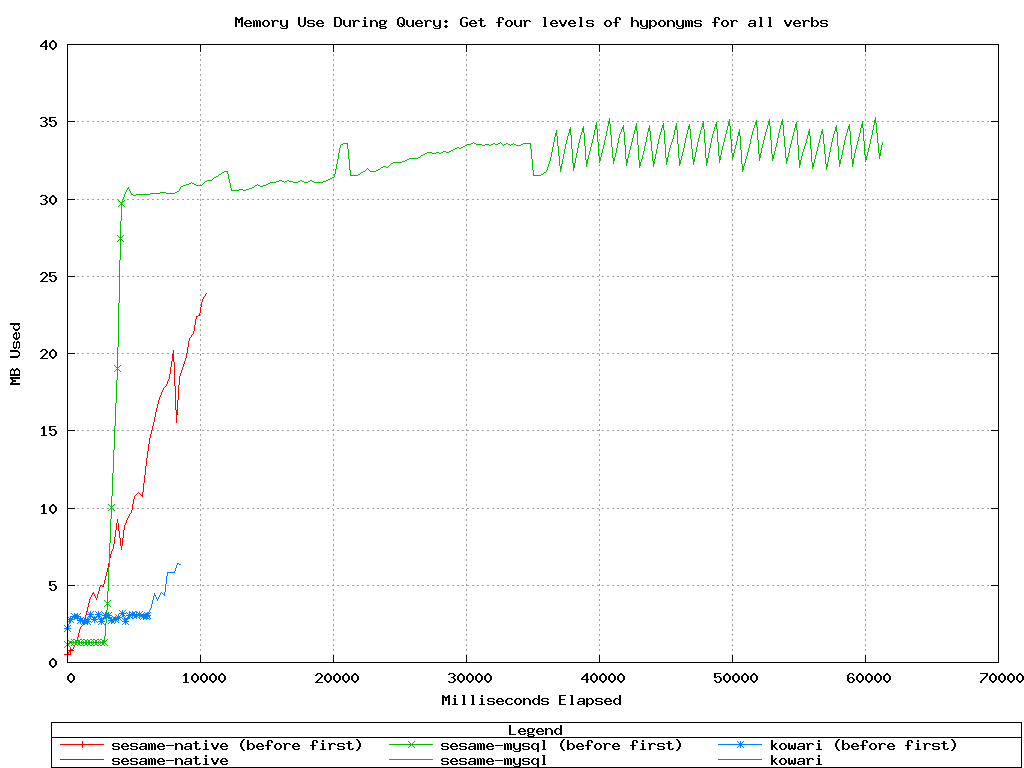
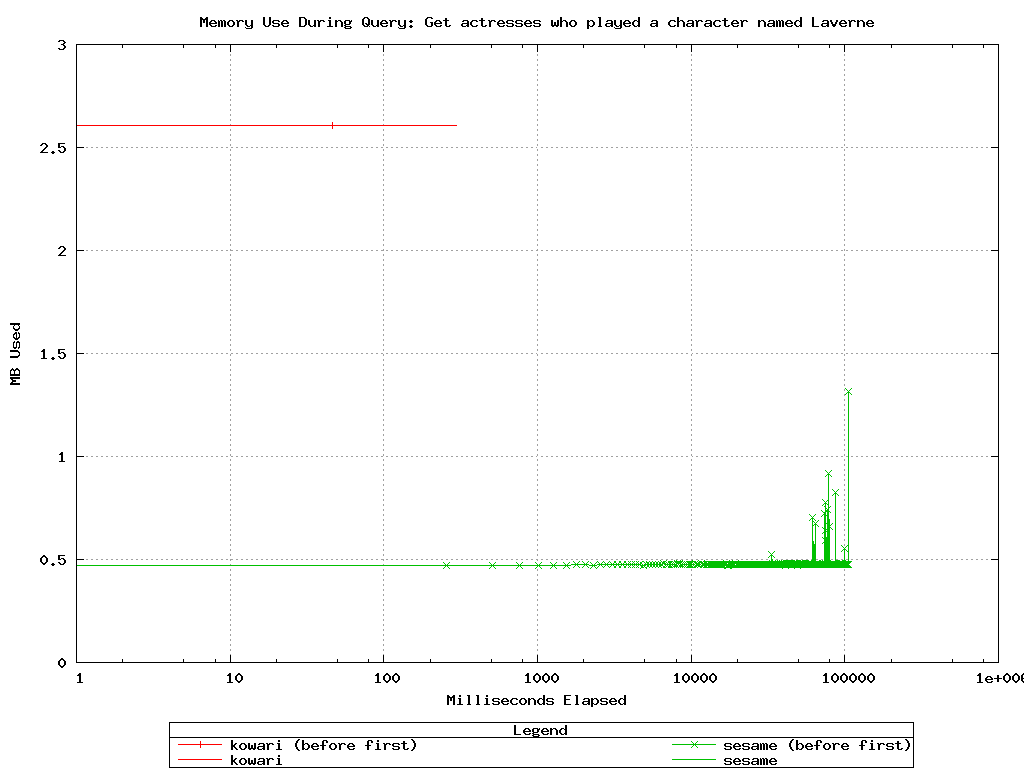
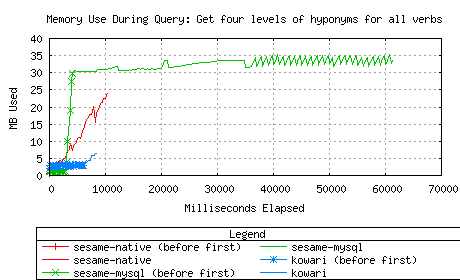
Kowari and Sesame-native performed impressively on this one. Notice
again how Sesame-MySQL takes up most of its memory before the first
result is returned.
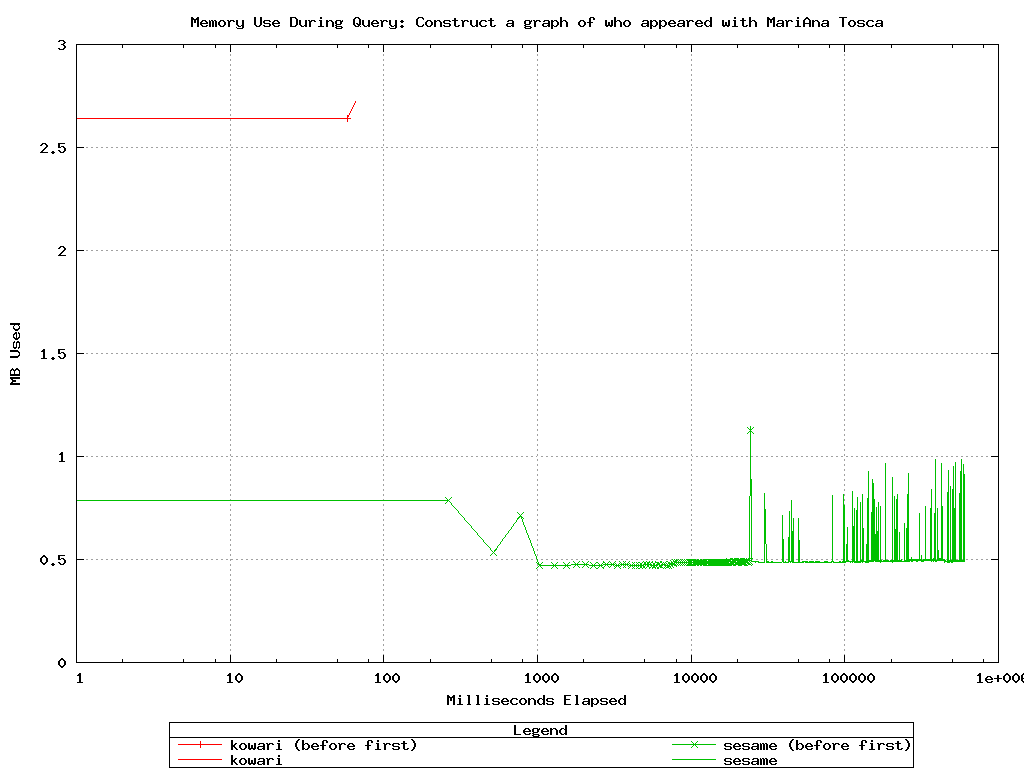
Having excluded Sesame-MySQL as an option for a large-scale triplestore,
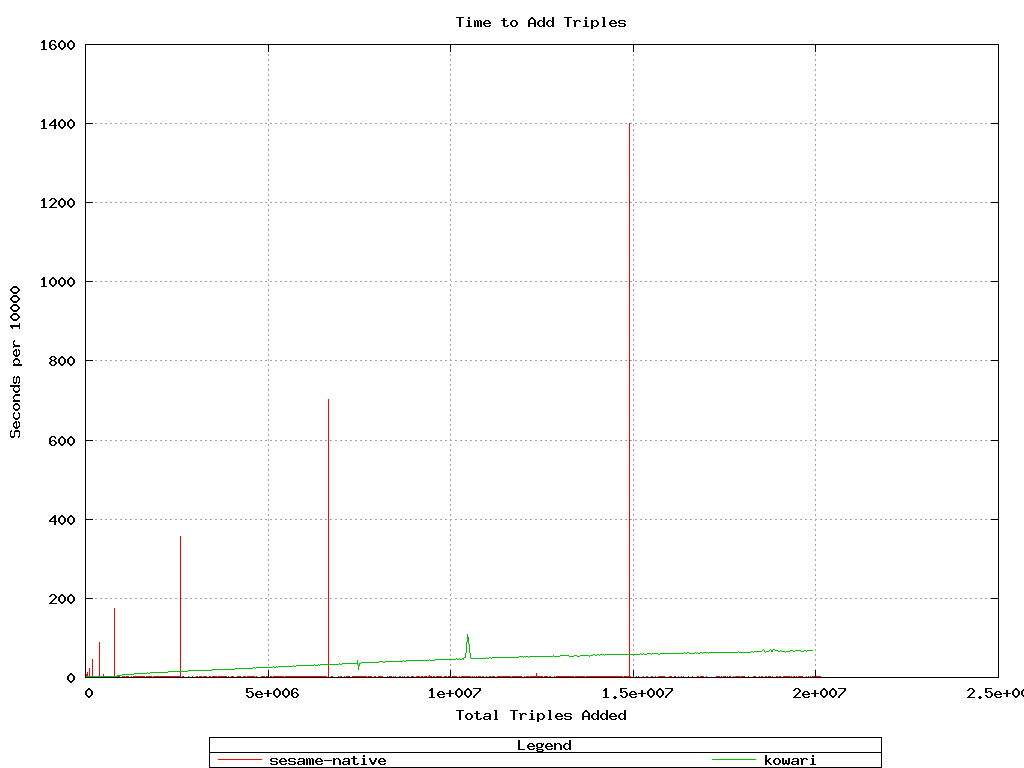
this test was intended to compare Sesame-native to Kowari. Unfortunately,
the test ran out of disk space when the Kowari load of 20M triples was
99% done (after about 24 hours), so only the add numbers up to that point
could be compared.
Query numbers are compared in the next (smaller) test.
Kowari's add performance degrades (linearly, at a low slope) with the number of triples
in the store. Sesame-native is much faster overall, but notice the
interesting pattern of spikes doubling in size at a decreasing frequency.
No guesses as to the cause of that.
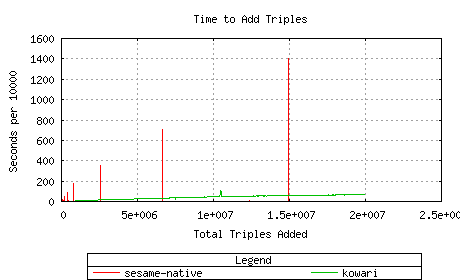
Again, these differences are explained by differing buffer sizes.